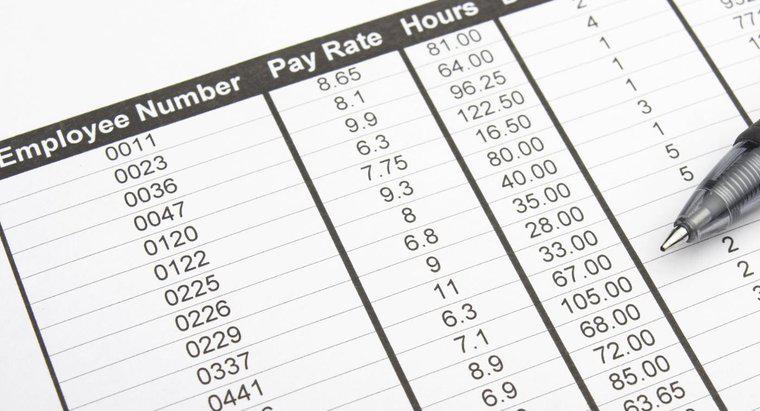
La caratteristica principale di un database relazionale è la sua chiave primaria, che è un identificatore univoco assegnato a ogni record in una tabella. Un esempio di buona chiave primaria è un numero di registrazione. Rende unico ogni record, facilitando la memorizzazione dei dati in più tabelle e ogni tabella in un database relazionale deve avere un campo chiave primaria.
Un'altra caratteristica fondamentale dei database relazionali è la loro capacità di contenere i dati su più tabelle. Questa funzione supera le limitazioni dei semplici database di file flat che possono avere solo una tabella. I record del database memorizzati in una tabella sono collegati ai record in altre tabelle dalla chiave primaria. La chiave primaria può unirsi alla tabella in una relazione uno-a-uno, una relazione uno-a-molti o una relazione molti-a-molti.
I database relazionali consentono agli utenti di eliminare, aggiornare, leggere e creare voci di dati nelle tabelle del database. Ciò si ottiene attraverso un linguaggio di query strutturato, o SQL, basato su principi algebrici relazionali. SQL consente inoltre agli utenti di manipolare e interrogare i dati in un database relazionale.
Le tabelle relazionali seguono varie regole di integrità che assicurano che i dati archiviati siano sempre accessibili e precisi. Le regole accoppiate con SQL consentono agli utenti di applicare facilmente controlli sulle transazioni e sulla concorrenza, garantendo l'integrità dei dati. Il concetto di database relazionale fu stabilito da Edgar F. Codd nel 1970.